
What is the architecture of an ideal agent?
Published:
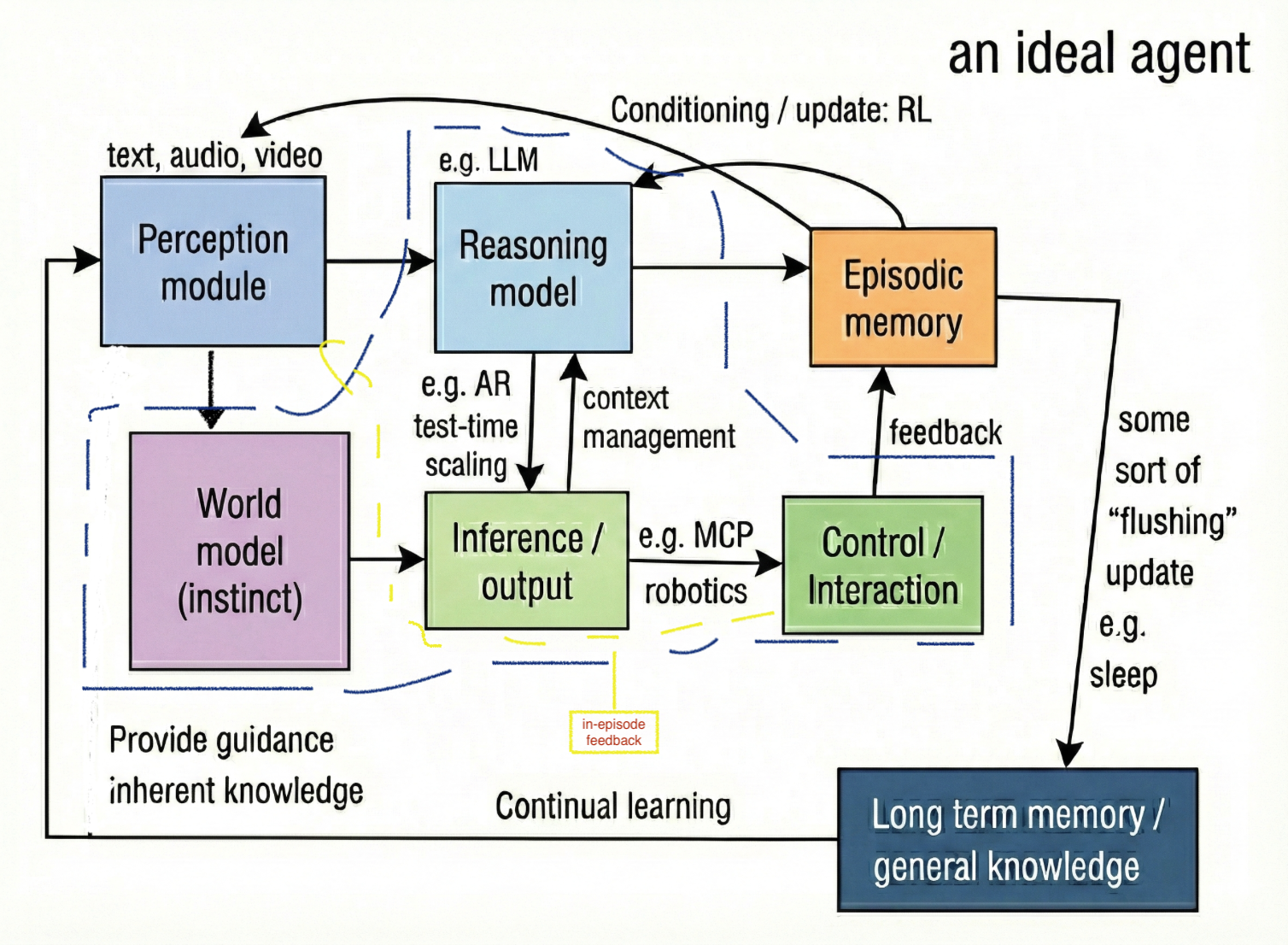
Here is a beta version of an ideal agent that I have been thinking about, this helps me personally to categorize a large amout of new ML research paper to one of the boxes or arrows, and to identify gaps.
- RLVR sits on the arrow from Episodic memory to Reasoning model
- Autoregressive sampling, speculative decoding, vLLM, any inference engine sit on the arrow from Reasoning model to Inference, two recent work on this arrow include TiDAR from Nvidia and power sampling from Harvard.
- The /compact command in Claude code sits on the arrow from Inference to Reasoning model.
- World model is largely missing, as the mainstream way to go from Perception to Inference is via Reasoning in language, but a world model with instinct should be a parallel channel.
- Control is pure engineering, protocals, and infrasture.
- Memory and context management is crucial for allowing the agent to run for a long time. This is a major gap.
For example: an instantiation of an agent, say Gemini 3:
- perception module: text, image, PDF, audio
- reasoning model: parameterized by a decoder-only LLM, with architecture design like MoE, a reasoning and planning layer etc, but overall transformer based.
- inference: autoregressive machine parameterized by the same decoder-only LLM to generate, various techniques, parallel thinking, CoT, etc
- context management: unknown
- world model: lacking, no instinct module or 3D predictive module built in as a parallel stream of inference
- control: can interact with UI once inference is done (or along with inference, streaming rendering), can interact with Google search API, can interact with VM code sandbox internally hosted by Google, can interact with IDE API such Antigravity
- not sure if MCP is used, but function calling, yes.
- robotics control is used in Gemini Robotics, with different upstream modules.
- episodic memory: the context window with various caching.
- feedback: non-existent as the model is frozen, no episodic memory, but in training, feedback exists in post training stage, where episodic memory is the whole inference + control history, then used to perform RLVR on the reasoning model
- long-term memory: exist, but very crude, basically a json file that tracks some facts about the user, specific to an assistant use scenario
- continual learning: doesn’t exist
- conditioned input from memory: exists in the crude way as how long-term memory is set up
Now this modular agent architecture allows for an internal (step) loop and an external (episodic) loop. The internal loop is boxed in my hand-drawn blue, corresponding to, say, a ReAct step. Note that within an episode, the state can change every time control/interation module is called, so it must emit a “in-episode feedback” to inform the perception module of the change, completing the internal loop.
The external loop is running the whole agent over different tasks end to end.
The external loop is parallelizable enabling large-scale and continual online learning, while the internal loop is predominantly (and reasonably) autoregressive.
Let’s analyze how Cursor maps to our modular agent setup:
- Perception: Same as the perception module in the base Reasoning model. But, they add a preprocess module even prior to perception, all the indexing, vectorizing, and aggregating stuff.
- Reasoning Model: for example, GPT-codex-5.1 for Ask and Agent mode. The interesting part is Cursor tab, which is backed by a separate smaller model that takes only local or partial perception input.
- World Model: missing due to irrelavance.
- Inference: autoregressively.
- Context management: prompt-based summarization as the AR inference hits a certain length.
- Control: Most engineering happens here. This module takes inference (specifically the tool call part) to interact with VScode API thus changing the state of the codebase (env), plus MCP servers and browser tools to realize inference to state transitions.
- Episodic memory: just context window. In-episode feedback is the return of tool calls, feeding back to perception at each ReAct step, and feedback (episode level) is missing.
- Long term memory: “flushing” and continual learning are missing, long term memory is implemented as .cursorrule which the perception module conditions on.
Voila, there we have a modular Cursor. Major things? Preprocess in Perception, in-house Reasoning model for a specific kind of task and input (tab), and implementing the control layer on top of VScode.
It’s also worth noting that, the Reasoning model box can contain multiple models, sometimes called a team of agents or agent workflow, such as plan-solve-verify workflow, this is within our scope as long as it is sequential, counting in an internal step.
In the case where multiple agents are spawned for sub-tasks, it’s better to treat them as different agents, as they can have different input/perception and different control.
Sequential agent workflow is well within reach whereas agent team is drastically different as the design of communication among modular agents is a massive topic.