
Agent Murphy
Published:
Recently my research lab built a custom agent running on a spare lower-end Mac mini box that my mentor happens to have. We call it Murphy, in defiant spirit to Murphy’s law and tribute to the beloved Interstellar.
Roughly two weeks ago, my mentor sent me a blog by Yuanming Hu about how he set up his agentic workflow to support his role plus engineering at Meshy. 10 Claude Code instances. Wow, that was incredible and full of words I couldn’t understand, so I decided to vibe code my own vibe coder, using Codex. Why Codex? Another major motivation was to extract maximum value from a ChatGPT Pro subscription, which frankly is quite generous.
So I built a prototype: communication via Slack, polls every few minutes, and executes a codex exec --yolo --ephemeral --skip-git-repo-check -<session prompt>, where the AGENTS.md file details how Slack MCP works, and this daemon just runs on the Mac mini, no security at all. This might sound insecure, but given that it’s on a spare computer and only working when we trigger Murphy from Slack, it turns out to be our implicit design principle: controllable research assistant.
Scrappy for sure but it works. Here are a few obvious issues:
- The daemon is thin, meaning each mention triggers a codex exec where the agent needs to fetch plenty of info via Slack MCP just to understand the task. We need a programmatic supervisor/dispatcher. Also it’s a waste of tokens.
- Research is our thing but Codex is inherently not optimized for research, yet ChatGPT Pro’s model seems quite good at it — math derivation, codebase audit, paper understanding, literature search, etc. Let’s wire that in without incurring API costs.
- Murphy is stateless; obviously a memory mechanism is needed. It should also maintain our goals so it becomes easy to resume a project. These are very intuitive features that one would request as a consumer without any expert knowledge in agent engineering.
So we resolved (not quite, as we will see) all of these:
- A daemon
supervisor.py, running with tmux. Now Murphy is only triggered when the supervisor dispatches a task that it polled periodically from Slack. Design philosophy: every thread is a task, supervisor polls global messages, but manages tasks. - Forked a ChatGPT MCP repo that works with the macOS Desktop app. Added persistent state files
long_term_goals.mdandmemory.mdunder.agent/. Cool, but we are far from all set. Turns out building a project like this without resorting to any doctrine is fun yet inherently iterative because of our short-sightedness. New issues come up:
- Daemon runtime is not modular, making it difficult to maintain. Had to refactor into multiple files.
- Kept patching the Desktop MCP but UI automation is way too brittle. Had to build a Chrome-based one from scratch with Playwright.
- Memory gets very cluttered and not beneficial. Had to switch to daily memory flushing into a curated memory hierarchy. More on the memory implementation — this part is still relatively simple even in today’s version, but we had a major win of an idea coming out of this: let the agent reflect and flush memory daily, not while it’s working. I guess you could say this is Murphy sleeping.
At this point, we started using it more in Slack for some actual tasks. For example, a workflow that I need Murphy to carry out is: research with GPT Pro → draft implementation plan + PR → ask for human audit → implement and get Codex review from PR → iterate → test → deliver.
Ok wow that’s a lot, and we quickly realized there are many gaps: can Murphy and I send files to each other via Slack? How does Murphy know that it should keep working on the PR rather than commit once and wait for a human? Or… should it be allowed to work autonomously? The Mac mini doesn’t have Nvidia GPUs — what if the tests involve LLM/agent training?
Well, the Slack attachment part is fairly simple; that functionality exists in the MCP server source code, let’s just expose it to the allowlist for Codex. No problem (in fact, problems there always are, as we will see later).
The iterative behavior one is interesting because Murphy started doing PR iteration with Codex PR review before I even attempted to wire this in. The only thing I put in was “you can use @codex in PR comments to request review” in AGENTS.md. But I decided later to wire in a loop mode on a thread level so a user can do @Murphy !loop-6h do something to ensure that Murphy works on this thread for at least 6 hours — whenever it quits, the supervisor re-dispatches the task forcibly.
As for GPU use, I just had to create an account for Murphy on our GPU node and give it credentials… Of course not so easy! I started adding a long behavioral contract in AGENTS.md about how to access with SSH and Slurm rules. This turned out to be not enough after Murphy brought the SSH connection down with a heavy flash-attn build, so ok, that got added to memory. No Docker bind mount / and no sudo access. I also hardened Slurm to forbid jobs from using more RAM than requested. Mild security.
So far AGENTS.md had ballooned to over 300 lines after trimming, and here comes some external help: I read the harness engineering blog from OpenAI and voila, we should use a tree of docs and AGENTS.md as a pointer plus behavior contract file! For example, regarding GPU use alone I had: storage hygiene, cache routing, large artifact placement, preflight checks, cleanup after completion, and job-stuck-PENDING sections in it. This is too much to keep in one file.
We switched to this structure: AGENTS.md # pointer file + core behavior contract ├── docs/ │ ├── protocols/ │ │ ├── slack-protocols.md # messaging rules, ACK, attachments, PDF delivery │ │ └── maintenance-protocols.md │ ├── workflows/ │ │ ├── git-workflow.md # commit rules, submodules, PR workflow │ │ ├── research-workflow.md # read-first sequence, consult, project folders │ │ ├── remote-gpu-workflow.md # SSH, Slurm, Docker constraints, resource limits │ │ ├── project-workflow.md # project folder creation and management │ │ └── skill-learning-workflow.md │ ├── mcp-integrations.md # consult server, Slack MCP │ ├── persistent-files.md # .agent/ file layout, artifact storage │ ├── schemas.md # outcome JSON, task JSON contracts │ └── operations.md # supervisor config, dashboard, hot restart └── docs/dev/ # developer-only (not Murphy’s domain) ├── CHANGELOG.md ├── ROADMAP.md ├── issues/ # bug reports filed by Murphy or humans └── plans/ # implementation plans for dev review
Many issues arise naturally in interactions and it gets more and more annoying to have to debug and audit the system, so we extended our previous “reflect daily” idea. Every 24 hours, the supervisor dispatches a special two-phase task:
- Reflect: Murphy reviews interactions from today for memory flushing and consolidation, identifies repeatable patterns to file as skills, and updates all documents.
- Dev review: Claude Code audits system source code for bugs, corrects and tests, ensures git hygiene, reviews and works on known issues and plans (for improving Murphy), and implements filed skills. A subtle but important detail: regular tasks use codex exec as the worker, but dev review uses
claude -p— different tools for different jobs. After dev review completes, the supervisor auto-restarts itself via os.execv (preserving PID) so any code fixes take effect immediately. You can also trigger a hot restart manually with kill -HUP or @Murphy !restart from Slack.
Examples that came out of the dev phase:
- Dev finds that developer_review.md was never injected into the phase 1 prompt.
- Dev finds that Murphy was using raw Slack API for attachments instead of MCP, indicating a stale MCP build, so humans need to decide if we want to rebuild and expose tools properly.
- Dev advances a plan to rewrite the project worker as a sub-agent rather than having Murphy navigate to the project, handle the real task, and do all the Slack business in one session. Due to multiple users, we also implemented parallel workers so two queued tasks can be dispatched concurrently. There were a few issues with how these workers merge worktrees back to main, but those were resolved by both humans and dev. We also drew a clear line between Murphy and dev by forbidding Murphy from editing its source code via git pre-commit hooks, but Murphy is allowed and encouraged to document issues, feature requests, and potential skills under
docs/dev/, which get picked up by dev in the next review phase.
Overall we ended up with this architecture. 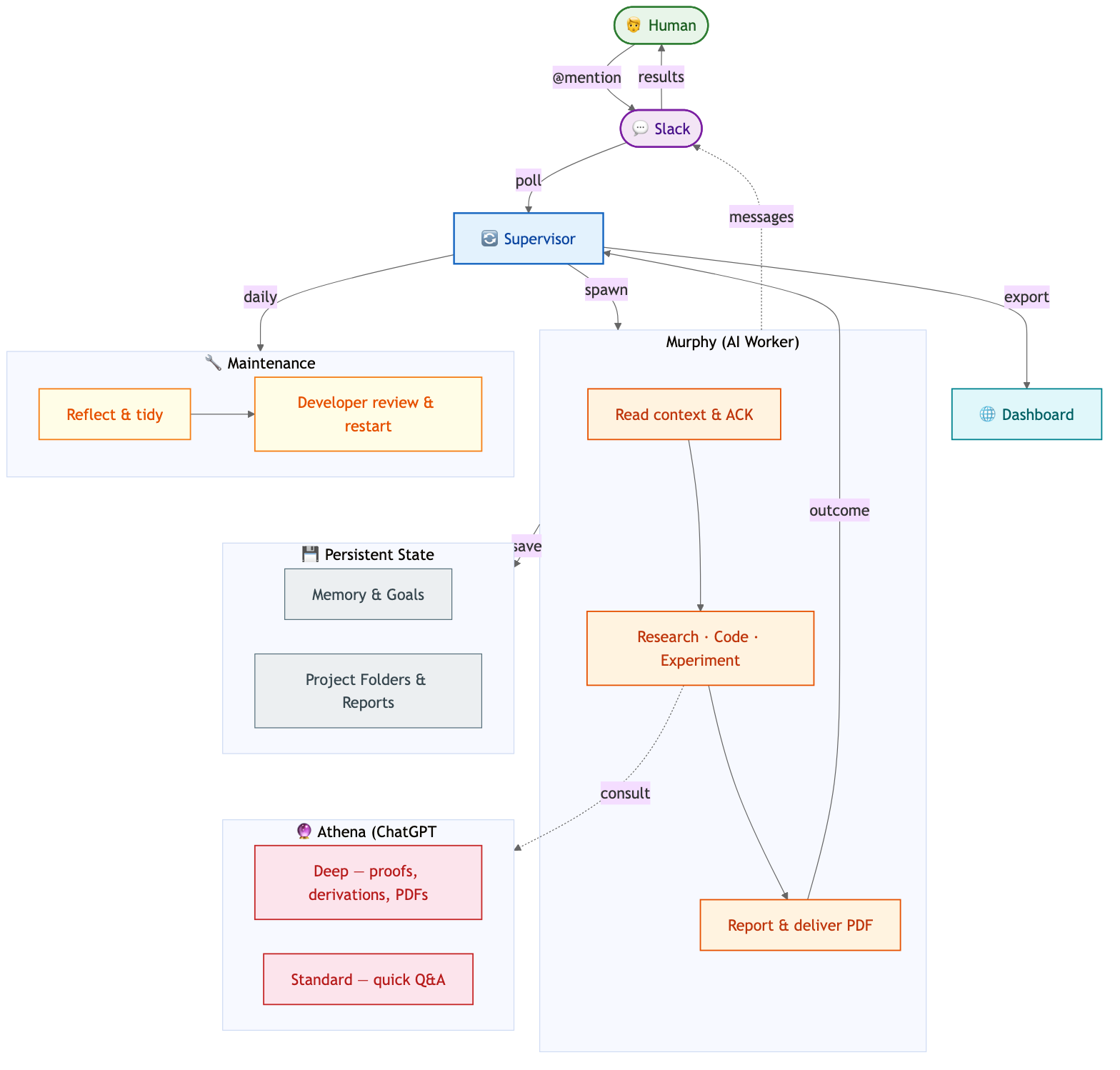
A few more things that rounded out the system:
The ChatGPT MCP is deliberately abstracted — Murphy knows it as “Athena,” an external expert, never as “ChatGPT.” The idea is that if we swap the backing model tomorrow, nothing in Murphy’s behavioral contract changes.
Thread context. Murphy is stateless per session, but the supervisor refreshes the full Slack thread context before every dispatch and snapshots all messages into per-task JSON files after each run. When Murphy is blocked on human input, the supervisor watches for new replies in the thread and automatically re-dispatches.
Beyond memory, we aggregate task conversations into per-project JSON files (.agent/projects/<slug>.json). A task tagged with a project slug gets its thread history synced into the project file, so Murphy can pick up context across sessions even for long-running research efforts.
Monitoring dashboard. The supervisor exports a static dashboard to GitHub Pages every cycle — live task state, heartbeat info, and even a remote GPU utilization snapshot via SSH. It’s simple but makes it easy to check on Murphy.
Skill learning. When Murphy spots a recurring pattern during reflect, it files a skill spec under docs/dev/. The dev phase picks these up and packages them as Codex-native skills in ~/.codex/skills/. It’s a modest self-improvement loop — Murphy proposes, dev implements.
[Mar 10th] still in progress, will come back with a GitHub repo later.